(UroToday.com) The 2024 SUO annual meeting included a prostate cancer session, featuring a presentation by medical student Nishan Sohoni discussing the classification of adverse events after prostate cancer hydrogel perirectal spacer insertion using large language models. The identification of treatment-related toxicity is essential for clinical research but is highly labor-intensive and subject to substantial variation when classifying events into pertinent categories. Large language models are promising tools for generating language and classifying unstructured text. Given their novelty, the application of large language models to the interpretation of adverse event reporting in medicine is underexplored. In this study, the investigators examined the performance of large language models to characterize the safety profile of an injectable hydrogel perirectal spacer used for radiation treatment of prostate cancer.
This study queried the US Food and Drug Administration’s MAUDE database to identify reported events related to perirectal hydrogel spacers between August and November 2023. Reports were manually classified by three trained reviewers using the following criteria:
- Primary and secondary adverse events (from a preselected category list)
- Presence of symptoms
- Radiation plan status
- Adverse event severity grade
Disagreements between reviewers were resolved by a board-certified urologist to create a gold standard document. Next, text large language model prompts were created to generate these classifications from the reports. Two types of prompts were created: in the first method (joint-prompt), all classifications for the same report were requested in one prompt. In the second method (split-prompt), each classification was requested in separate prompts. The large language models GPT-3.5-Turbo, GPT-4-Turbo, and GPT-4o were evaluated. Each (prompt, model) combination was run three separate times per example, then compared to the gold standard, along with the human reviewers.
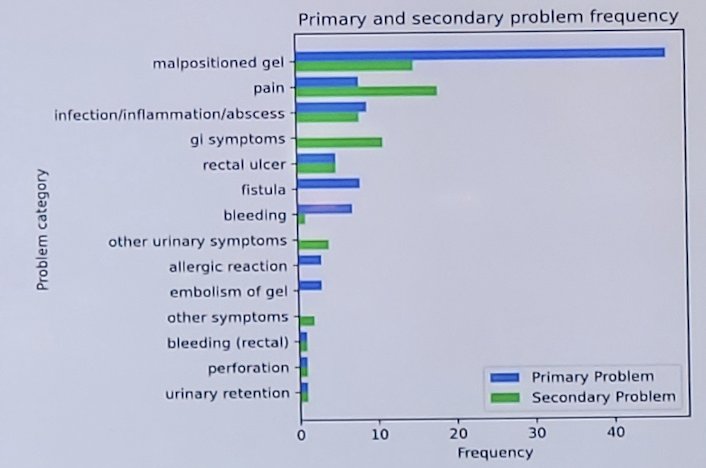
Among the 97 cases reviewed, the most common primary adverse events identified in the gold standard were mal-positioned gel (47/97), pain (9/97), and infection/inflammation/abscess (8/97):
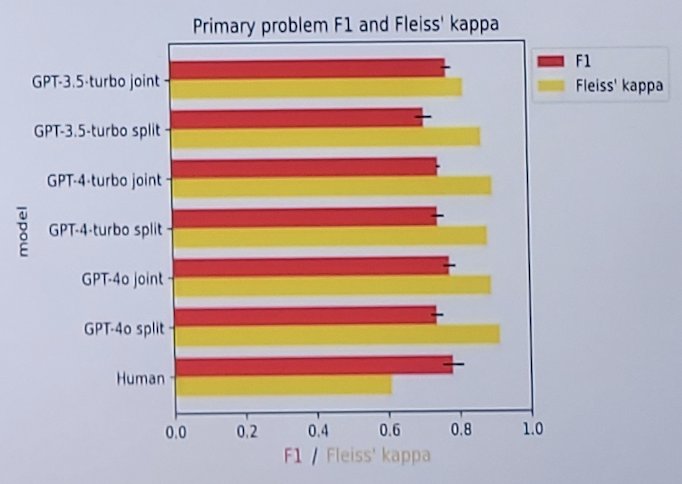
Average F1 scores (a measure of precision and recall) for primary problem identification were: 0.782 (human, 95% CI: 0.756-0.810), 0.777 (GPT-4o joint, 95% CI: 0.761-0.792), 0.739 (GPT-4o split, 95% CI: 0.723-0.755), 0.749 (GPT-4-Turbo joint, 95% CI: 0.743-0.755), 0.746 (GPT-4-Turbo split, 95% CI: 0.730-0.761), 0.777 (GPT-3.5-Turbo joint, 95% CI: 0.765-0.789) and 0.711 (GPT-3.5-Turbo split, 95% CI: 0.691-0.732). The corresponding Fleiss’ Kappa scores for the primary problem (a measure of inter-rater or intra-model reliability, where higher scores indicate greater agreement across raters), were: 0.609 (human), 0.894 (GPT-4o joint), 0.916 (GPT-4o split), 0.901 (GPT-4-Turbo joint), 0.885 (GPT-4-Turbo split), 0.823 (GPT-3.5-Turbo joint), and 0.872 (GPT-3.5-Turbo split):
Several limitations were noted for this study:
- The gold standard document used the responses of the same reviewers being assessed, potentially introducing bias
- While the manufacturer and importers of SpaceOAR are required to report adverse events, healthcare services only do so at the discretion of the providers. Thus, such analyses may over or underrepresent certain adverse events
Nishan Sohoni concluded his presentation by discussing the classification of adverse events after prostate cancer hydrogel perirectal spacer insertion using large language models with the following take home messages:
- The identification of ground truth even by human reviewers was often challenging in the MAUDE database, with only moderate agreement between reviewers. The identification of ground truth was thereby subject to the consensus of multiple reviewers and validated by further review of a board certified urologist
- Prompt design and engineering are crucial, and adherence to principled and more advanced prompt engineering guidelines will be essential to unlock the full capabilities of these models moving forward
- Large language models could potentially be deployed to assist in the characterization of prostate cancer treatment-related adverse events, with similar accuracy and reduced interrater variability compared with manual classification
Presented by: Nishan Sohoni, Yale School of Medicine, New Haven, CT
Written by: Zachary Klaassen, MD, MSc – Urologic Oncologist, Associate Professor of Urology, Georgia Cancer Center, Wellstar MCG Health, @zklaassen_md on Twitter during the 2024 Society of Urologic Oncology (SUO) annual meeting held in Dallas, between the 3rd and 6th of December, 2024.